- Open-source
- Dashboard
- API
Request
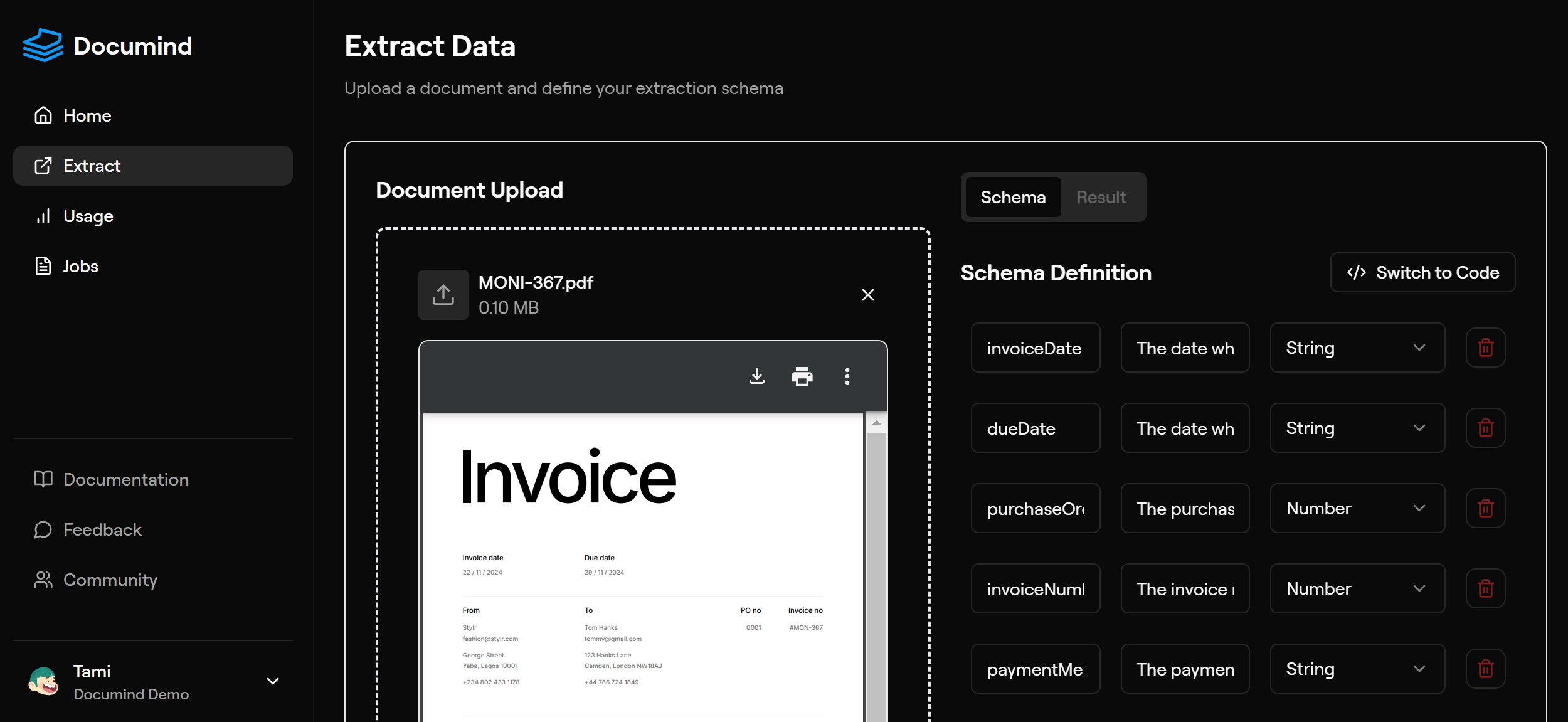
Let’s run a sample extraction with the Documind open-source package.Parameters
Currently, only URLs are accepted. Ensure your document is hosted and accessible via a public URL.
The file URL.
The schema that defines the structure of the data you want to extract. Read more on how to define a schema.
You can select a template schema that matches your document. [Template options] (/guides/templates/overview)
Use autoSchema to auto-generate your schema
Example Output
Once the extraction process is complete, the result will return a structured JSON object with the extracted data:Indicates whether the extraction was successful or not.
The number of pages processed in the document.
The extracted data based on the schema.
The name of the processed file
The markdown of the file